Compression
The other day, I was watching Silicon Valley on HBO where they were talking about Compression. As the fans will recall, Richard Hendricks invented a compression algorithm so powerful that it can compress your data to the extent where you can access them "instantly" on any device with the most primitive network connections - thus, making the world, a better place. The compression algorithm, named Pied Piper, is said to have a Weissman Score of 2.9 in Season 1 and later improved to a score of 5.2 on Season 3. So what is all this? Let's examine.

Compression Algorithms
Compression can be defined as the process of reducing the number of bits required to represent a data. How can this be achieved? Let us take an example. Say we have the following text -
ABBBCCBABAABCCAABA
This data can also be represented as -
A2B1CBAB1AB1C1ABA
The original string was 18 characters long and the new string is 17 characters long. So that is a compressed string. We can translate the compressed string back into the original string by substituting the numbers appearing before a character the number times with the character. For example, 2B becomes BBB and so on. Although this is not of much use to us, it provides a good understanding of what a compression algorithm tries to achieve.
However, data is not always structured and does not always exhibit repetative patterns. The best compression algorithms on the market prey on just that - repetative patterns in the data. But compression of data varies depending upon what the data represents too. For instance, an algorithm designed for text compression cannot be expected to provide good image compression because the two types of data differ by a wide margin.
When we deal with compression, we classify algorithms into 2 broad categories:
- Lossy Compression - Whereby the original data is not guaranteed to be kept exact throughout the compression/decompression cycle, i.e, a part of the data may be lost. This is mostly used in images where an average color of a block of pixels may be applied to all the pixels in the block thereby reducing the file size but also (almost unnoticeable) losing the pixel data from each pixel in the block (ex. JPEG).
- Lossless Compression - Whereby the original data is retained to the bit throughout the compression/decompression cycle. Usually used in text compression.
So let's get down to the various data compressions -
Top 10 Compression Algorithms -
- BZIP2 - The BZIP2 program is a free and open-source general purpose single-file compression algorithm developed and maintained by Julian Seward. This program offers a better compression ratio at the cost of speed. It may as well be the slowest among the top existing text compression algorithms. Read more
- DEFLATE - This is a lossless data compression algorithm first developed and introduced in PKZIP v2.0 by Phil Katz. This compression algorithm compresses the raw data into blocks with 3-bit headers. While this achieves a lower compression ratio as compared to BZIP2 accross multiple test cases, it does have much higher compression speed. Read more
- LZMA - The Lempel-Ziv-Markov chain Algorithm is a lossless data compression algorithm for general purpose use that was first introduced in the popular free compression tool 7-Zip. This offers a comparable compression ratio to BZIP2 while also keeping the decompression speed comparable to that of DEFLATE. Read more
- LZHAM - The LZMA compression tool was good. But it made a decent tradeoff in terms of speed for achieving higher compression ratios. The LZHAM compression tool optimizes this tradeoff for a notably fast decompression speed. Read more
- GZIP - This is by far the most widely used compression algorithm for all web apps on the internet. The main reason for this is that it has the fastest compression/decompression speed although a little short on compression ratio among all the existing general purpose compression programs. It is also found to be the most reliable compression algorithm. Read more
- ZLIB - The ZLIB Compression algorithm is lossless data compression algorithm that holds much similarity to the GZIP compression algorithm. However, it achieves greater compression ratio essentially by stripping off the unnecessary headers and footers in the GZIP compression. It is also a part of the three HTTP compression standards but is not widely used due to faulty support in Internet Explorer. It is however, used by gaming consoles like PS3, Wii U, Xbox 360, etc. Read more
- PAQ - The PAQ is a series of compression algorithms that have achieved massive benchmark compressions over the years. While these remain very resource intensive, they also offer an equally astonishing compression ratio. A notable of a PAQ algorithm (PAQ6) was in the KGB Archiver compression/decompression tool by Tomasz Pawlak. Read more
- CMIX - This is a new lossless data compression tool that aims to achieve benchmark compression ratios at the cost of high CPU/Memory usage. Developed and maintained by Byron Knoll, so far it has achieved great success. Read more
- Zopfli - Developed and maintained by Google, the Zopfli compressor achieves a great compression ratio by combining existing DEFLATE, GZIP and ZLIB compression algorithms at the expense of compression time. This can be thought of as an optimal mix of benchmark compression algorithms and fast compression algorithms. More recently, Google announced a new data compression algorithm that surpasses Zopfli. Read more
- Brotli - While Zopfli was a mix of existing data compression tools, Brotli is a whole new tool built from the scratch. It fares better than most existing general purpose compression algorithms achieving optimal scores in all aspects. Google even released a benchmark test between Brotli and the other top compression algorithms which you can view here. Google plans to integrate this compression standard in the web platform. Read more
The Weissman Score
Throughout the series, Silicon Valley, the characters use the Weissman Score to judge the compression algorithm. But, what is this Weissman Score? Is that really a thing? Turns out it is. It was formulated by Tsachy Weissman, a professor at Stanford, and Vinith Misra, a graduate student, under the request of the producers of Silicon Valley.
As you now may understand, no one compression algorithm can be called "The best" because it always boils down to a tradeoff between speed and compression ratio. However, in order to convey this to a general audience, we need a term of art. The Weissman Score is just that. It factors in both the compression ratio and the speed to determine which of two compression algorithms are better and by how far. While I cannot vouch for it's validity, it does provide a better way to explain to the audience how awesome "Pied Piper's compression" is.
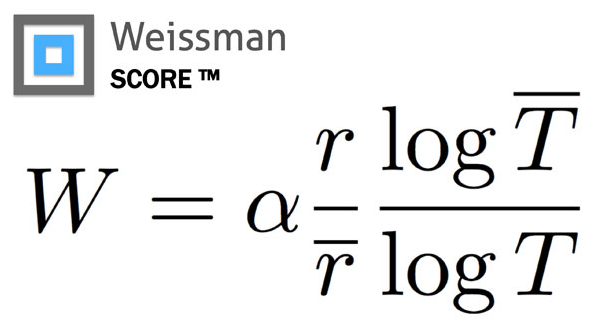
With the help of 7-zip, Zopfli and ptime, I was able to calculate the Weissman score of some of the top compression algorithms. Taking the Zip compression as the standard for comparison and alpha as 1.0, this is a table of my results.
| Format | r | T (in seconds) | W |
|---|---|---|---|
| Zip | 1.842955 | 0.413 | 1.000000 |
| 7-Zip | 1.772706 | 0.603 | 1.681566 |
| Gzip | 1.960958 | 0.554 | 1.593201 |
| BZip2 | 2.055101 | 0.395 | 1.061615 |
| Zopfli DEFLATE | 2.001594 | 2.046 | -1.341592 |
| Zopfli GZip | 1.982632 | 1.958 | -1.415829 |
As is clear from the table, the limitation of this scoring is clearly apparent. Although the standard defines any value for alpha can be used, choosing a value of 1.0 or more can result in negative values of score as in the table above. This limitation is listed on it's Wikipedia Page in the following words -
Although the value is relative to the standards against which it is compared, the unit used to measure the times changes the score (see examples 1 and 2), and the multiplier also can't have a numeric value of 1 or less, because the logarithm of 1 is 0 (examples 3 and 4), and the logarithm of any value less than 1 is negative (examples 5 and 6); that would result in scores of value 0 (even with changes), undefined, or negative (even if better than positive).